



Modern web automation is changing, and new automation tools are emerging into the market. New tools provide a bundle of features for End-to-End Testing, API Testing, and Component testing. Interestingly some of the tools even started utilizing Artificial intelligence and codeless automation. Most of the automation shares one important thing which is the locator. Despite this commonality, automation testers can easily get confused when they have to decide between the two most popular locators XPath and CSS locator. In this tutorial, we will provide an in-depth comparison of XPath vs CSS selector to help testers make an informed decision.
Table Of Contents
- 1 What is Locator?
- 2 What is XPath?
- 3 Basic XPath Expression and their Meaning
- 4 Advantages of XPath
- 5 Disadvantages of XPath
- 6 How to create an XPath?
- 7 How to check the correctness of the XPath expression in the Browser?
- 8 What are CSS selectors?
- 9 Types of CSS Selectors
- 10 Advantages of CSS Selectors over XPath
- 11 Disadvantages of CSS Selectors over XPath
- 12 Differences between XPath vs CSS selector
- 13 Which is best XPath vs CSS Selector?
- 14 XPath vs CSS selector for Test Automation
- 15 Frequently Asked Questions
What is Locator?
Locators are used to select the specific element in the DOM tree. Automation tools rely on locators to find almost every component or element on the webpage. Tools require a unique identification of the element on the webpage to perform any action on it, and the locator is used to match the element based on the provided locator expression.
Locators can be broadly classified into two types.
- XPath Locator
- CSS Locator
XPath and CSS locators have existed for many years and all major browsers, frameworks, and programming languages support them. One can easily get confused and might have questions like which locator is better, CSS selector, or XPath Selector. Instead of concluding directly, it would be better to try to understand and analyze XPath vs CSS selector in detail. By examining the pros and cons of each locator, we can determine which is the best possible choice for a given situation.
What is Xpath?
XPath stands for XML Path Language. It is a query-based syntax for XML schema and HTML documents that testers use to traverse elements within the document. Expressions refer to the values used in XPath, and an expression typically contains the chaining of multiple elements with a specific syntax or structure.
Let’s understand the types of XPath
Absolute Xpath
The absolute XPath starts from the root of the HTML or XML document and starts with a single slash (/).
Relative OR Dynamic Xpath
The Relative XPath can start anywhere in the DOM tree, it starts with a double slash(//)
Xpath Axes
XPath provides axes, these are special keywords that can be used in XPath expression. It is used to locate the node relative to the current node in context.
For example, if you need to select the parent of the current node in context, you can construct the XPath like below.//div[@id=”abc”]/parent::*
Basic Xpath Expression and Their Meaning
- /: Selects the root of the node
- *: Select any element node
- . : Selects the current node in the given context
- //: Selects the node from the current node that matches the selection
- ..: Parent of the selected node
- @: Selects attribute
- @*: Select any attribute
- Node(): select any node
Advantages of Xpath
- XPath supports all major test automation libraries and programming languages
- It provides bidirectional flow which means traversal can be both ways
- Supports both XML and HTML documents.
- XPath expression works at any document level, with no restriction to start the traversal at a specific level
- It is the declarative expression not procedural; this helps to use any indexes and different types of axes/functions efficiently to select the specific node
- XPath selector is compatible with old-age browsers as well as modern browsers
- XPath locator provides Axes and methods. You can use them in XPath expression to solve complex locator problems.
Disadvantages of Xpath
- The performance of the XPath varies from application to application. As a matter of fact, experts say that XPath locators are comparatively slow, which can affect the overall performance of the test suite.
- It cannot solve the modern world shadow DOM problem.
- XPath is associated with more than one element in the DOM tree, and it tends to break as and when new element-level changes are introduced.
- Usage of indexes (specific nodes with numbers) within the XPath causes high maintenance (Ex: //div[1]).
- If XPath gets complicated more it becomes untidy and readability decreases
How to Create an Xpath?
You can easily create XPath using any browser developer tools, nowadays, almost every browser comes with rich developer tools, and also supports XPath expressions.Note: As mentioned earlier there are two types of XPath absolute and relative, usage of absolute XPath is not recommended and not used by many. One of the reasons is absolute selectors starts from root of the HTML element, any new changes in the DOM element can easily break the XPath and since it starts from root, it results in slow performance. Relative XPath is used more widely and has a huge user base.Let’s understand constructing an XPath expression with the help of a popular browser chrome.
Step by Step Guide to Create Xpath
Consider the scenario where you need to navigate to Testsigma and get the XPath for the Testsigma logo
1: Navigate to Testsigma using the Chrome browser.
2: Right Click on the Testsigma logo and click on inspect to open the dev tools.
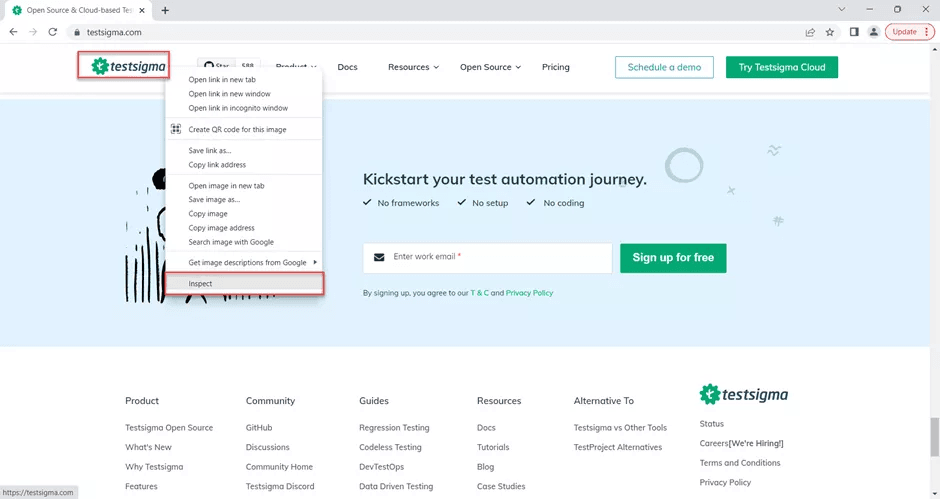
3: Ensure that Chrome dev tool is opened with an active tab Elements.
4: Use CTRL + F, inside the dev tool to bring the search input.
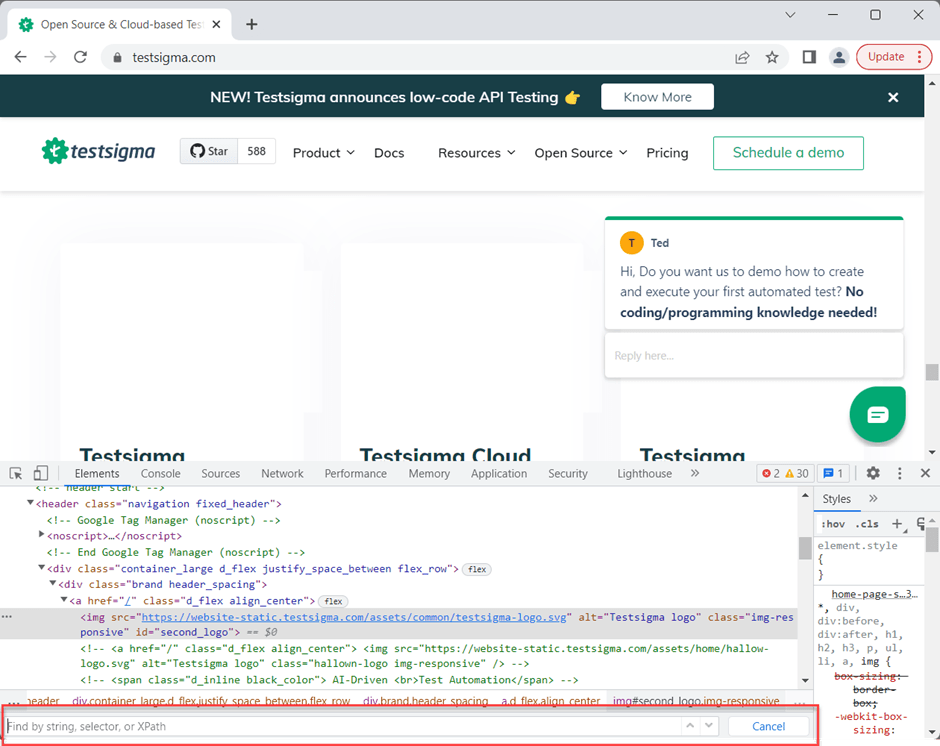
5: Start constructing the XPath expressionYou need to construct the XPath based on the XPath expression rules or syntaxes. However, the developer tools are friendly, and it can help you to validate the correctness instantly by highlighting the selected node on the user interface.In the given scenario, you need to find the XPath for the Testsigma logo, so look for the HTML element containing the test sigma logo.

The above image shows the HTML code for the Testsigma logo, as you can see it is a <img> containing attributes like alt, class, and id.
Let’s construct the XPath based on the idXPath expression looks like below.//img[@id=’second_logo’]
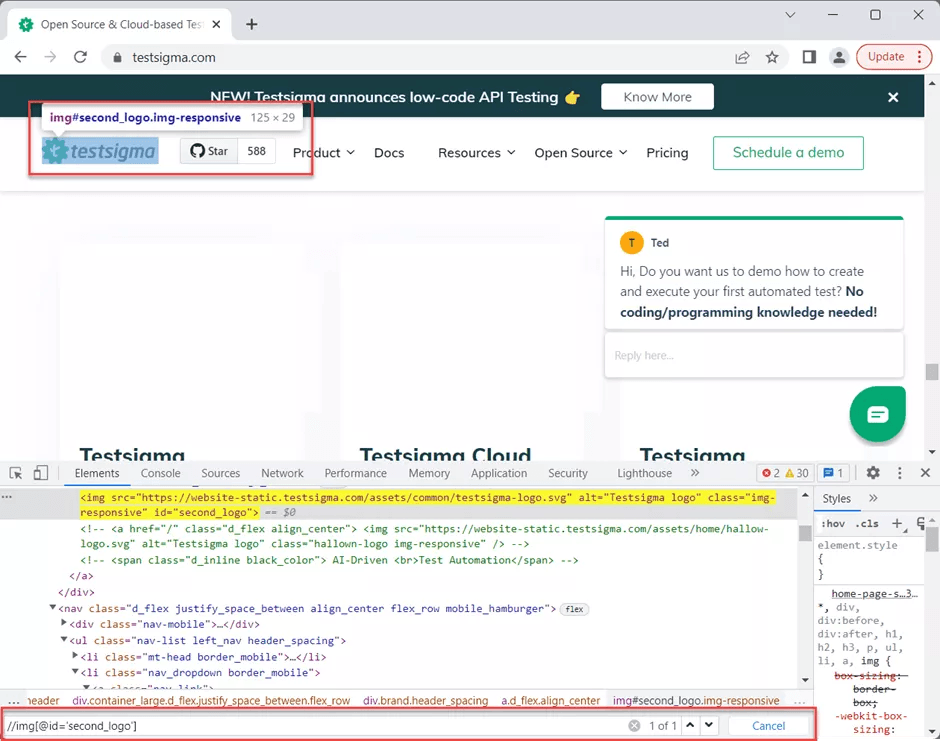
As you can see in the image, Once you enter the XPath expression for the logo in search box, the Testsigma logo is highlighted in the user interface, which means the entered XPath is correct.
How to Check the Correctness of the Xpath Expression in the Browser?
To check the correctness of the XPath in the browser there are two important points
- XPath expression in the browser developer tool search box must match at least one element (Ensure that it is a required element).
- Once you entered the valid XPath expression, the specific UI element must be highlighted.
If none of the above criteria meets, consider rewriting the XPath expressions.
What Are CSS Selectors?
CSS selectors are type of locators, it follows the string representations of the HTML elements such as tags, attributes, and classes. Similar to XPath, CSS also follows specific syntax for the selector expressions. It also helps to find the elements on the webpage uniquely.
Types of CSS Selectors
- Element selector
- ID selector
- class selector
- attribute selectors
- Universal/wildcard selectors
Before jumping into an explanation for CSS selector types, let’s have a glance at some expressionsTable: CSS Selector expression and their usage
| Selector | Example | Description |
| # | #id1 | Used for selecting the element with id |
| . | .class1 | Used for selecting the element with class |
| [ ] | img[alt=’abc’] | Used for writing the attribute-based CSS selectors |
| > | div>button | Used for writing the attribute-based CSS selectors |
| + | div + button | Used for selecting the element that is placed immediately after the first one (div) |
| ~ | div~nav | Used for selecting the element that is preceded by the second element (div) |
| [attribute*=value] | a[href*=”testsigma”] | Selects elements which are containing the attribute value |
| [attribute$=value] | [href$=’.docx] | Selects an element that’s element value ends with the attribute value |
| [attribute=value] | [alt=’abc’] | Selects an element with the exact match of the attribute value |
| :nth-child(n) | div:nth-child(2) | Selects the nth child Just like the index in XPath |
Let’s go through the selectors in detail:
CSS Element Selector
Element selector selects the HTML element based on the tag name such as p, div, img, etc.
Example: div
CSS ID Selector
You can select the HTML element based on the id attribute of the specific tag. The # (hash) is used as a prefix for the id selector.
Example#myid
CSS class selector
The class selector selects the HTML element based on the class attribute. The “.” (dot) is used as a prefix for the class selector
Example: .myclass
Universal Selector
The * is used for selecting all the elements within the HTML doc.
Attribute Selector
Attribute selector is used for selecting the HTML element based on the attribute type and value
Example: img[alt=’abc’]
Advantages of CSS Selectors over Xpath
- CSS Selectors are faster in comparison with XPath.
- These selectors are more readable and easier to learn.
- CSS selectors are compatible with all modern browsers.
- It works across devices and responsive screens.
- CSS selectors are more reliable as it is mostly tied to single HTML element.
Disadvantages of CSS Selectors over Xpath
- CSS is unidirectional; it allows node traversal from parent to child only. When there are complex scenarios, it is difficult to construct locators.
- CSS selectors don’t provide methods to handle complex element locators as we have the Axes method in XPath.
- If the application doesn’t include the attributes for the element in the DOM tree, writing a CSS selector will be difficult, and it may become unreliable.
- You cannot construct the selectors based on visible text.
How to Create CSS Selectors?
Like XPath, all modern browsers support CSS selectors. One can create CSS selectors using the browser developer’s tools. Mozilla Firefox, Microsoft Edge, and Google Chrome all browsers provide a rich developer console that helps create CSS selectors. You can validate CSS selectors for correctness by checking UI highlight and element selection numbers within the developer console.
Let’s take a scenario of writing the CSS selector for Testsigma Logo in the webpage testsigma.com
Steps by Step guide to creating CSS selectors
1: Navigate to testsigma.com using the Chrome browser.
2: Right-click on the TestSigma Logo and click on inspect.
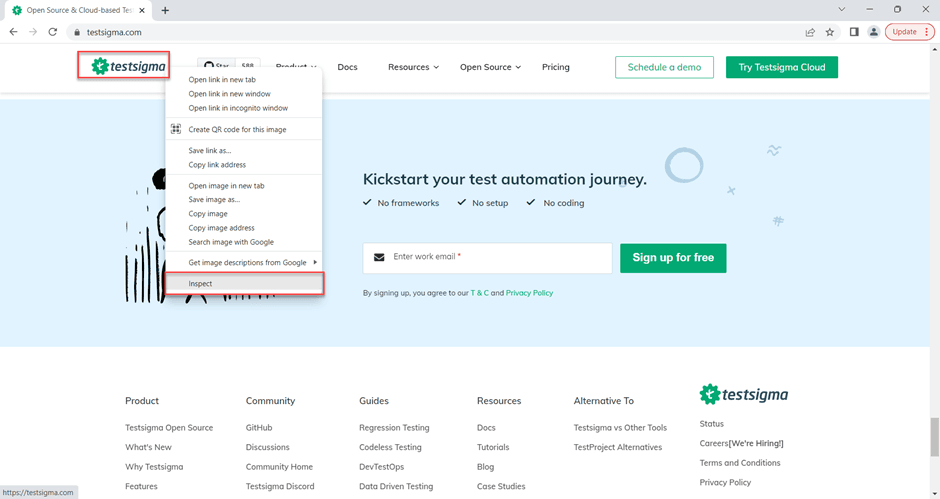
3: Press CTRL + F to bring the search box input into the developer tools4: Write the CSS selector
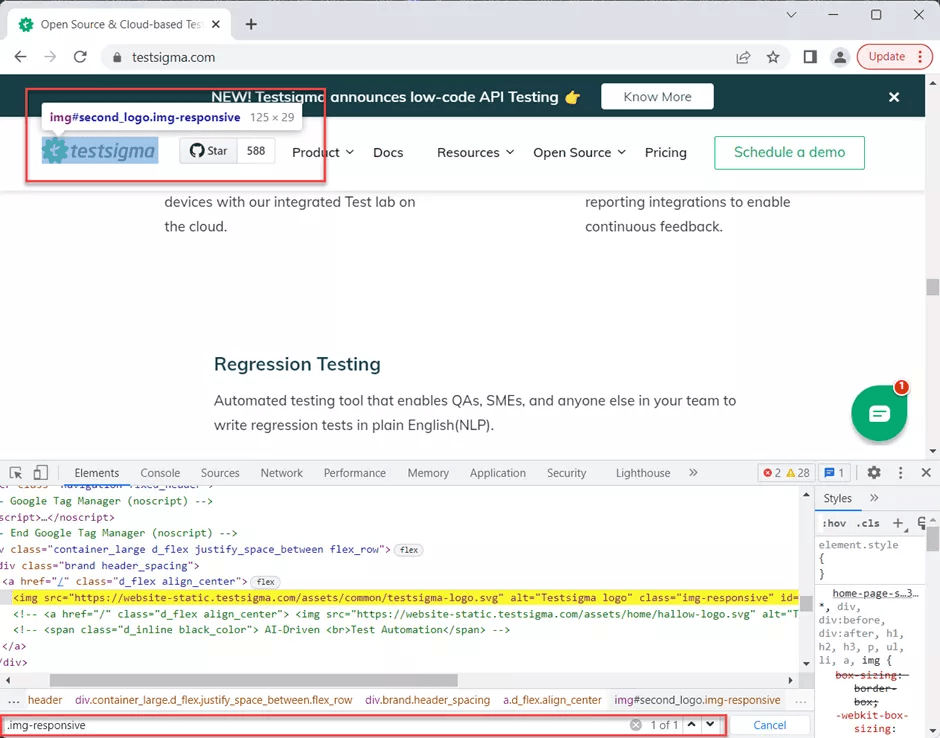
Write the CSS selector as per CSS selector rules. For example, if we take a look at the DOM tree for the logo, it’s a <img> tag and contains the id, class, and alt attributes.
Based on the availability of the attributes and tags, you can construct below CSS selectors
CSS ID selectors
Just use # and the id.
Example of ID selector
#second_logo
CSS attribute selector
You can also use the alt attribute for this selector
Example of Attribute selector
img[alt=”Testsigma logo”]
CSS class selector
Since this tag also includes the class name you can choose to use the class name for the selector
Example of class selector
.img-responsive
Note: While performing the automation test, you need to specify either one of the selector but not all.
Differences between Xpath Vs CSS Selector
Table: Differences between XPath and CSS Selector
| XPath Selector | CSS Selector |
| Xpath is bidirectional you can traverse elements from parent to child or child to parent | CSS selector is unidirectional you can only traverse from parent to child |
| XPath is slower in terms of speed and performance | CSS selector is comparatively faster |
| XPath allows the construction of text-based selectors | CSS doesn’t allow to construct the text-based selectors |
| XPath should start with / or // followed by a tag name or wildcards like * | CSS allows to directly direct some of the attribute-based selectors such as # for id and . for classes |
| XPath provides Axes to solve complicated selector problems | CSS doesn’t have any Axes methods |
| Xpath is less readable as it grows | CSS Selectors are more readable |
Which is Best Xpath Vs CSS Selector?
CSS and XPath selectors are widely used in automation testing. However, choosing XPath or CSS depends on the application architecture, rendering of the web pages, etc. For example, if there is no element with unique attributes and you need to select the element based on visible text, then you need to use XPath; in another case when you have an id, class, or any other unique attribute available at the element level, using XPath may complicate the framework. So, you can simply go for the CSS selectors. Considering the above scenario, you can see that choosing XPath vs. CSS Selector is purely based on the design of the application, the availability of the attributes in the DOM tree, and the complexity of the element structure.
Xpath Vs CSS Selector for Test Automation
Typically any automation framework supports both CSS and XPath-based selectors. To make your automation framework more stable and consistent, have a checklist of when to use what. Regardless of the multiple locator options, writing the locator requires technical knowledge and proficiency. Both XPath and CSS selectors can be created in multiple ways; creating more stable and unbreakable locators is most important. Modern AI-based test automation frameworks like Testsigma cloud offer automatic construction of selectors in the background, you just need to record the test cases. This tool eases the test engineers’ tasks and increases productivity. It records the selectors and provides an option to edit and customize locators.
Frequently Asked Questions
Why Do CSS Selectors Have Higher Priority over Xpath Expressions?
Unlike CSS selectors, XPath selectors are associated with more than one node (element) in the DOM hierarchy; thus, introducing any DOM-level changes can easily break your changes. CSS is associated with fewer nodes, and it is more stable. Experts suggest using the XPath only if there is no way to write the CSS selectors.
Which One is Faster, CSS OR Xpath?
CSS selectors are faster compared to XPath since they are unidirectional; they are able to search for elements in the DOM tree more quickly.
Which is the Strongest CSS Selector?
The CSS ID selectors are most preferred over any. The reason is: ID is associated with a single HTML element, and is unique.

