



Data is the new asset for any business use case for drawing insights. Similarly, Automation Testing is the new standard that tech companies set for testing their software products.
XPath plays a vital role in any of the uses above, in scraping data from multiple websites or testing products and functionality. XPath allows testers like us to navigate around various locators of the web page with the help of numerous properties such as ID, Tag Name, Group Index, and Predicates.
This blog post walks you through various examples of XPath locators and their definitions.
We have shown the Java implementation of the XPath locator in our cheat sheet for Selenium locators. Let’s begin with this comprehensive XPath cheat sheet, which will be quite helpful while performing automated testing or scraping data through Selenium.
Table Of Contents
What is Xpath?
XPath is the path of elements on the HTML tree. XPath allows us to use different selectors on the HTML page.
We represent the current webpage in XPath by using(.) and (/) to represent child elements to navigate through different elements in HTML and XML documents.
The Xpath Syntax
Since we’ve discussed XPath, let’s check how we can generate XPath. The example below shows XPath syntax with single and multiple attributes.
XPath Syntax for Single Attribute
//tag[@AttributeName = ‘Attribute Value’]
XPath Syntax for Multiple Attributes
//tag[@AttributeName1=’Attribute Value’ and @AttributeName2=’AttributeValue2’]
//tag[@AttributeName1=’Attribute Value’ or @AttributeName2=’AttributeValue2’]
Different Types of Xpath in Selenium
XPath allows us to navigate through the webpage in two different types:
- Absolute XPath
- Relative XPath
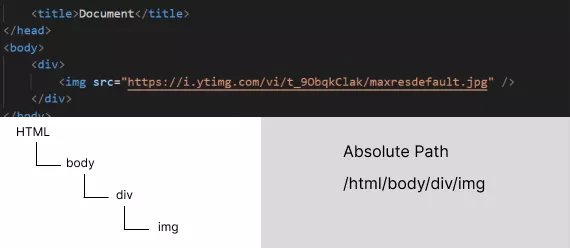
Absolute Xpath
This locator uses the whole expression from the parent tag and starts with a single tag representing child elements.
Below attached is one more example of using a selector with multiple divisions. In such cases, we can use the index in the path. We define the array index inside the bracket according to the node position.
Example:

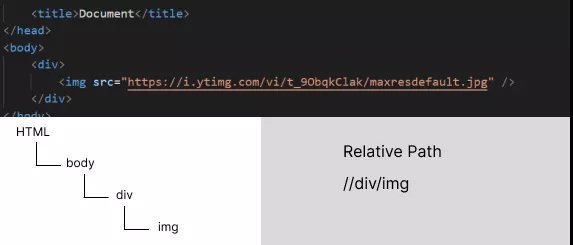
Relative Xpath
Relative XPath can start from anywhere from the HTML structure. We use Relative XPath when we don’t want to write the complete XPath expression from the root node.
The Relative XPath starts from a double forward slash, whereas the Absolute XPath starts from a single slash.
Example:
In the below example, we are choosing the image selector. Unlike Absolute XPath, we need not start from HTML.
Xpath Expressions in Selenium
XPath expressions navigate and select appropriate elements in HTML and XML documents.
| Symbol | Definition |
| / | The single forward slash is used for selecting the child element,to create absolute XPath, to select elements from the root node, and to traverse through child elements from the parent node. |
| // | The double forward slash symbol is used for the descendant child(child,grandchild,etc.)in relative paths to select any elements present in the document. |
| . | The single dot selects the current node. |
| @ | Select attributes |
| //a/.. | Backward traversing is where we use (.) dot notations to go up the tree or reach the parent node.The expression attached will get the parent element of the anchor tag. |
Xpath Selectors in Selenium
XPath selectors allow us to select a specific part of HTML documents.
Descendant Selectors
To select child elements of the current parent node, Descendant selectors are used. We use a double forward slash or single forward slash to select the child or grand-child elements in the HTML.
The Syntax for Descendant selectors:
/tag or //tag
Attribute Selectors
Attribute selectors are used for elements based on the attribute present in a single HTML node.
The Syntax for Attribute selectors:
//tag[@AttibuteName= ‘Attribute Value”]
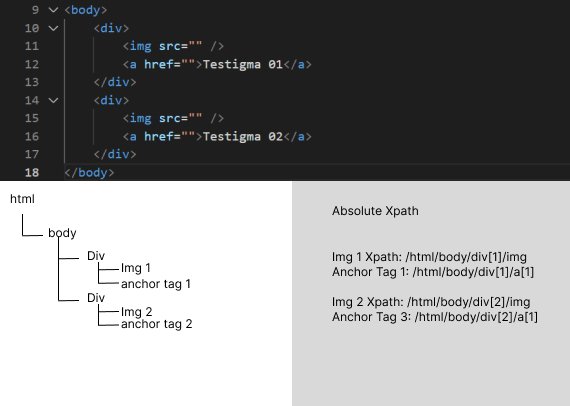
XPath by Group Index
XPath by Group Index is used to match a single element. We write the index inside the bracket and the elements outside the block element.
It executes the XPath inside the brackets and stores the matching elements in the XPath array. Then, it will identify the elements based on the index from the elements mentioned outside the bracket.
Example: If we follow the XPath by Group index, we can get a single result of our Choice.
Axes in Xpath
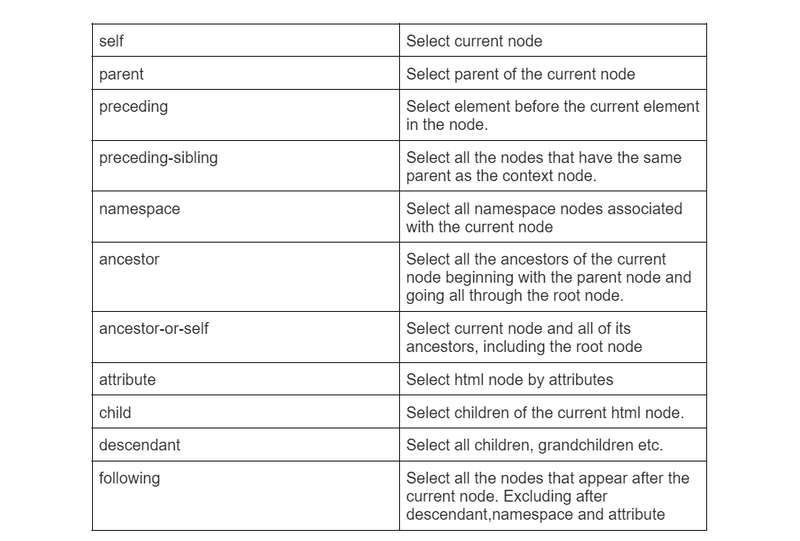
Axes represent the relationship between the current element and its relative element. It could be anything, such as a child or sibling, parent nodes etc.
Functions in Xpath
A set of operations can be used for making Functions in XPath. It could be adding two HTML or getting the count of images present in a webpage.
Node Functions
XPath has several node functions such as name(), text(), position(), last(), comment() and name(). This Function provides the name of the HTML node.
Xpath=//[starts-with(name(), ‘h’)]
text()
This function is used to locate the HTML elements based on the text of the web element.
Xpath=//td[text()='login']
comment()
This function selects the elements with comments.
/span/comment()
last()
This function selects the last element in the current Node.
/span/img[last()]
position()
This function provides the position of the element.
Ex: (//a)[position() ≤= n]
Operators in Xpath
We can use operators combined with XPath to check certain conditions and verify requirements. It behaves like the if-else condition. XPath predicates come in square brackets after the parent elements are tested. With the following attached XML below, we’ve provided different examples for the operator:
- Greater than(>)
- Less than(<)
- OR operator ( OR )
- AND operator ( AND )
- Not Equal to ( != )
- Equal to ( = )
<eCommerce>
<mobile>
<Iphone supplier="mother" id="1">
<year>2020</year>
<amount>1000</amount>
<store>ABC</store>
</Iphone>
<Samsung supplier="store" id="2">
<year>2018</year>
<amount>700</amount>
<amount>700</amount>
<store>XYZ</store>
</Samsung>
</mobile>
</eCommerce>
Less than operator ( < )
We can use this operator with XPath to check if the result is less than the number
Example:
eCommerce/mobile/iphone[year < 2019]
Result: In this expression, all the phones are listed with a year Lesser than 2019.
Greater than operator ( > )
We can use this operator with XPath to check if the result is greater than a number.
Example:
eCommerce/mobile/iphone[year > 2019]
Result: In this expression, all the phones are listed with a year greater than 2019.
Equal to operator ( = )
We can use this operator for comparing or checking if the value is equal to the expected value.
Example:
eCommerce//[@store=’ABC’]
Result: In this expression, all the stores with the name ABC are listed. Thus, the result will be an iPhone.
Not Equal to operator ( != )
We can use this operator to check if the operator is not equal to the expected value
Example:
eCommerce//[@store!=’ABC’]
Result: In this, we will have all stores not named ABC. The result will be Samsung.
AND operator ( and )
We use this operator in cases where we want both conditions to be true.
eCommerce//[@store=’ABC and @store=’XYZ’’]
OR operator ( or )
We use this operator in cases where we want any one of the conditions to be true.
eCommerce//[@store=’ABC or @store=’XYZ’’]
//input[@value=’A’ or @value=’B’]
Browser Console to Locate Xpath
We can test our XPath in browsers before checking it programmatically. With the help of debugging tools such as a console, we can test our XPath in the console.
We can write our XPath or with help of an inspector, we can get the XPath of any element on the webpage.
To validate XPath programmatically, follow these steps:
- Visit any website (for example, Testsigma) and press F12 on the keyboard.
- Click on the console as shown in the image below.
- $x(“//img[@class=’img-responsive’]/@src”)
- Entering the above XPath, we can select the Testsigma logo element on the left top corner as shown in the below image.
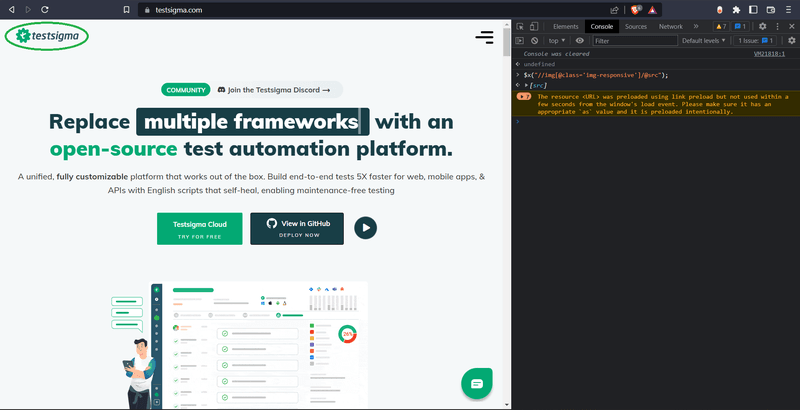
Validating XPath with help of inspector XPath:
- Visit any website and press F12 on the keyboard.
- Click on Elements and right click element of your choice
- Hover the cursor over Copy and select Copy full XPath.
Once done we can place the copied XPath inside the $x(`place your XPath copied from elements`) and check your results.
Wrapping up
XPath is used to select or find elements on a webpage. We can use XPath in combination with other programming languages as well.
XPath allows us to navigate through the webpage in two different types:
- Absolute XPath.
- Relative XPath.
Relative XPath is more reliable and efficient while testing or scrapping a webpage. Since it supports dynamic operations, we can continue to extract data or automate tasks using the same code, even if the website is updated.
Frequently Asked Questions:
The easiest way to find XPath is by using browser developer tools. Follow the below steps to generate XPath quickly.
1. Right-click on the element of your choice and select inspect, This will launch the inspector tool for elements HTML code.
2. Copy the XPath by right-clicking the HTML element.
3. Test the copied XPath to locate the same element in Chrome.
The Relative XPath is faster in Selenium than the Absolute XPath. Absolute XPath is slow because it starts from the root node. Relative XPath is faster and most preferred because it starts from the middle of the HTML structure.
Relative XPath is best in major scenarios as there’s minimum code maintenance required if there’s any update on the website.

